I Built an AI UX Reviewer That Costs $3.50 Per Run
How I built QuorumUX — an open-source tool that uses multi-model AI consensus to find UX issues in Playwright recordings for less than a coffee.
I spent last weekend building a tool I've wanted for months. It watches screen recordings of real user flows, analyzes every screenshot & video session, and tells me exactly where my app's UX is broken...prioritized by severity, backed by multi-model consensus. The whole thing runs from a single CLI command and costs less than a coffee.
It's called QuorumUX, and it's open source.
The Problem That Wouldn't Go Away
I'm building MomentumEQ, a values-driven career development platform. As a solo technical founder, I wear every hat...architect, engineer, PM, and yes, QA. I had Playwright running end-to-end tests across 10 different user personas. The tests caught regressions. What they didn't catch was friction.
A button that technically works but takes 6 seconds to respond. A tooltip that obscures the element you're trying to click. An onboarding flow where users can't tell how many steps remain. A mobile dialog where the text area is behind an invisible overlay.
These aren't test failures. They're the kind of silent UX erosion that makes users leave without filing a bug report. I was catching some of them by manually scrubbing through Playwright video recordings at 2AM, but that doesn't scale and my eyes glaze over by persona #4.
I wanted something that could watch the same recordings I was watching, but with infinite patience and zero ego.
The Idea: Disagreement as Signal
Here's the core insight that makes QuorumUX different from "throw GPT-4 at a screenshot."
Any single AI model will hallucinate UX issues. It'll flag things that aren't problems and miss things that are. But when you send the same screenshots to Claude, Gemini, and GPT-4o independently and then have a fourth model synthesize their findings...something interesting happens.
Issues flagged by two or more models are almost always real. Single-model findings need human review. And when models actively disagree about whether something is a problem, that disagreement itself is useful signal...it usually means the UX is ambiguous enough that real users will be split too.
This is the "quorum" in QuorumUX. It's consensus-weighted severity, not a single model's opinion.
What It Actually Does
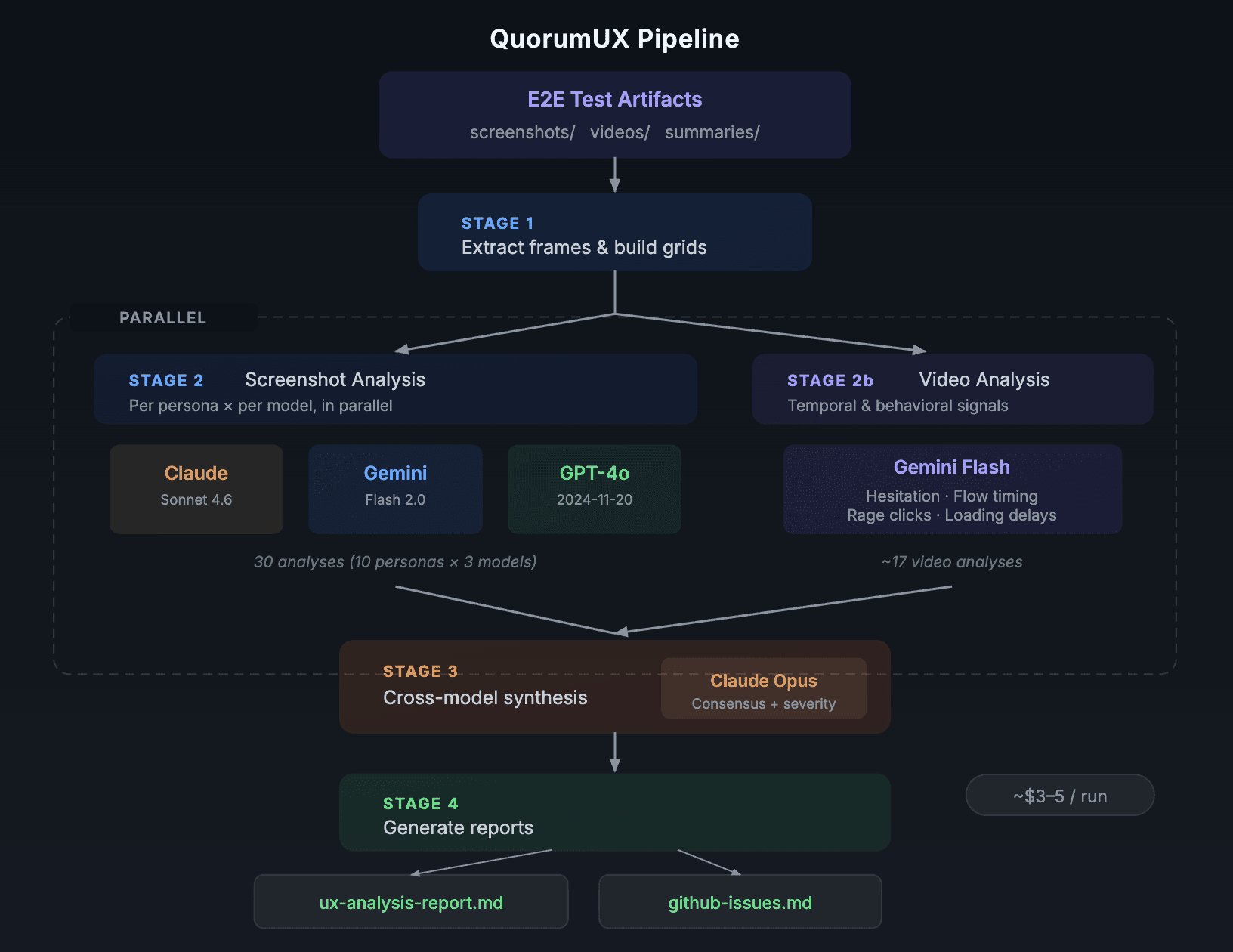
The pipeline has four stages:
Extract — Takes your Playwright artifacts (screenshots + video recordings) and processes them. Screenshots get composited into per-persona grid images. Videos get frame-extracted via ffmpeg. No AI calls yet, just prep.
Analyze — Three vision models independently review every persona's screenshot grid plus their test summary (pass/fail/friction counts). Each model produces a structured list of findings with severity, location, and recommended fix. In parallel, Gemini watches the raw video recordings and catches temporal issues that screenshots can't: hesitation patterns, rage clicks, loading delays, confusion backtracking.
Synthesize — Claude Opus receives all analyses from every model, cross-references them, and produces a single unified report. Each issue gets tagged with how many models flagged it and whether video evidence supports it. Severity is consensus-weighted: a P0 from all three models with video confirmation is very different from a P2 flagged by one model.
Report — The synthesis gets formatted into a markdown report, a JSON sidecar for CI integration, and ready-to-paste gh issue create commands for every finding.
One command. Ten personas. Three models plus video. About 12 minutes. Around $3.50.
What I Learned Running It Against My Own App
I've run QuorumUX against MomentumEQ five times now. The first run scored 65/100. The latest is tracking around 58...which sounds worse, but the scoring got more honest as I improved the tool's ability to separate real app issues from test infrastructure noise.
Some things that surprised me:
Video analysis catches what screenshots miss. My static analysis showed the login flow as "PASS" because the page loaded and all elements rendered. The video analysis caught that it took 6.2 seconds for returning users and nearly 9 seconds for first-time logins. That was a P0 I would have shipped to production.
Test bugs poison your signal. Three of seven P0s in one run were actually Playwright test infrastructure problems...a page evaluate scoping bug, a URL serialization issue, and a null input error. They looked like app failures but were test failures. I added a classification system in v0.3.0 that separates test-infra issues and weights them at 0.25x in the score so they don't mask real UX problems.
The compare command changed my workflow. Being able to diff two runs and see which issues were resolved, which persisted, and which are new...that turned QuorumUX from a point-in-time audit into a continuous improvement loop. I can now prove to myself (and future stakeholders) that the last batch of fixes actually moved the needle.
Why Open Source
I built QuorumUX to solve my own problem. But the architecture is intentionally generic: it consumes test artifacts, not test code. Any project that produces screenshots and video from Playwright, Cypress, or Puppeteer can use it.
The broader bet is that multi-model consensus is an underexplored pattern for AI-assisted quality. We've all seen the "vibe check" demos where someone asks ChatGPT to review a screenshot. Those are fun but unreliable. Consensus mechanisms make AI review rigorous enough to actually trust in a development workflow.
If you're a solo founder, a small team without a dedicated UX researcher, or just someone who wants automated UX regression detection in CI...give it a try.
npm install -g quorum-ux
quorumux init
quorumux --dry-run
The repo is at github.com/dadcoachengineer/QuorumUX. MIT licensed. Issues and PRs welcome.